
Blogs
DataWeave – Transformations Made Easy
DataWeave is a new language for querying and transforming data. DataWeave includes a connectivity layer that is different from other transformation technologies.
DataWeave is a new language for querying and transforming data. DataWeave includes a connectivity layer that is different from other transformation technologies.

Apache Solr is one of the powerful open-source search libraries available in the market. In this article, we will discuss on how to set up a Solr cluster.

Custom Processing using Apache Pig UDFs (User Defined Functions). Pig UDFs can be easily implemented in Java.

Classification is a supervised learning technique that learns, builds experience from the existing categorised documents and tries to predict a category to previously unseen data.

The Spark Cluster can be setup in multiple ways – Standalone mode, Using Hadoop YARN, Using Apache MESOS and Using Amazon EC2.

In Big Data, a Data Driven Enterprise can be defined as the one that is capable of validating what is known, confirming what is unknown and discovering the truly new.
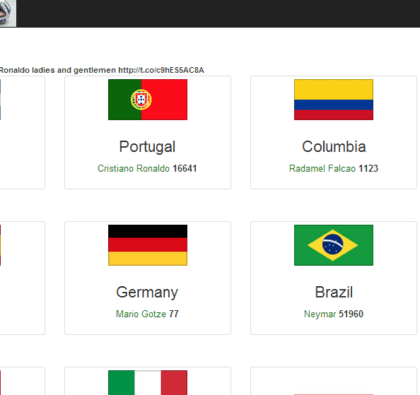
Here are millions of soccer fans across the world that follow the WorldCup closely, following their favorite footballers, teams and watching every game.

WHISHWORKS, a forerunner in Big Data consulting services is the proud sponsor of The Big Data Innovation Summit 2014, London UK.

Everyone has experienced Recommendation Systems on the web. In YouTube, we are automatically presented with a list of recommended videos.