
Blogs
How to optimise Azure Data Lake Integration Using MuleSoft
In this blog about Azure Data Lake integration, we’ll focus on uploading file data using Azure Data Lake Connector.
In this blog about Azure Data Lake integration, we’ll focus on uploading file data using Azure Data Lake Connector.

Why do users choose Amazon DynamoDB? What you’ll need to get started and highlights of the functionality in DynamoDB made possible by Mule 4.

Retrieving and processing huge amounts of data from the source to the target? We have an option called Streaming in DW to help you.

Exploring the challenges facing Telecommunications and the digital solutions set to transform the industry in 2021 and for the future.

If you want to improve your business processes and unlock new revenue streams, it is vital that you move to a more data-driven approach.

Security best practices in Microsoft Azure ensure your infrastructure is resilient while safeguarding user access and protecting customer data.

Since 2019, key developments such as COVID-19 have influenced investment trends in Big Data. Drawing on insights from WHISHWORKS’ Big Data Report 2020 we outline the key drivers of investment in Big Data this year.
In this blog, we will explore the recommendations for running Zookeeper in replicated mode and why this is the best method for using Zookeeper within your Apache Kafka implementation. Zookeeper […]

This article is for non-technical readers who have little or no technical background and want to understand the basics of Apache Kafka.

A guide on using Terraform with Microsoft Azure, exploring capabilities such as building a CI/CD pipeline, codifying the configuration for SDN and more.
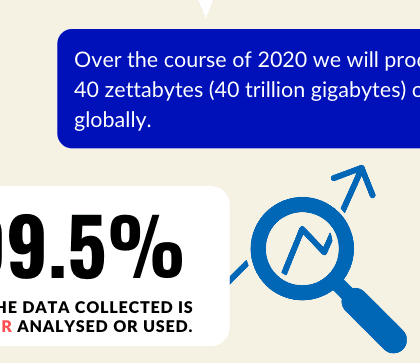
In this blog, we look at the key statistics around the use of data and the role of Big Data Analytics in 2020 and beyond.

WHISHWORKS partners with HPE/MapR and Confluent to drive democratization of services in the Big Data space.